
VLA 司机模型【司机Agent】最后落地一定是一个端云一体化的产品【车端VLA 4B+云端 32B VL基座模型】。车端OrinX Thor 算力有限且需要低时延反应,车端的VLA模型参量就一定大不到哪里去,因此一定需要用COT 的方式将部分复杂场景分析放在云端VL模型中,将信息分析下放回车端完成完整的Token输出后用扩散模型转换成轨迹再转换成控制单元。
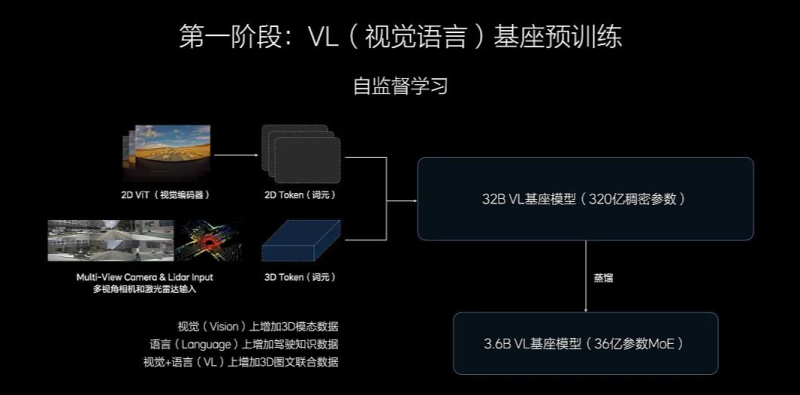
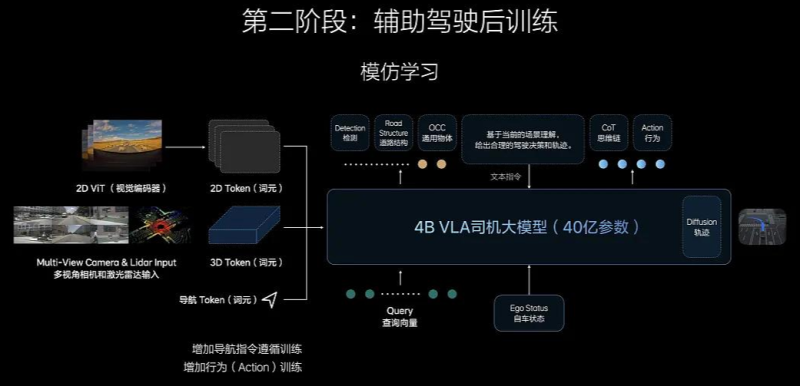
VLA的VL基座模型为什么要自己去预训练。如果不是用原生的基座模型。模型蒸馏以后其他LLM模型里面和驾驶场景无关的知识能力客观来说会影响模型本体的能力上限。【而车端算力是非常宝贵的,因此做原生驾驶场景的基座模型就是一个非常艰难,但是必须要做的事情】【当然如果某一家可能会有更高的车端算力,我觉得尝试用第三方LLM去做蒸馏后强化学习也是可以尝试一下,毕竟各家搞科研的VLA机器人都是用开源的LLM】

VLA 相较于 E2E+VLM最大的两个差异:
1)是没有双系统协同了,所以不需要用VLM去指挥E2E;
2)VLA因为所有信息都是转成了Token在进LLM【蒸馏后的基座模型,这里简化描述。部分复杂指令会上云进VL模型】,因此多模态信息对齐在自动驾驶领域第一次达成【实时视觉感知、语义信息、导航信息、驾驶员需求信息等等】。
用VLA可以让,AD系统真的看懂、看清楚、理解【车机导航】,注意是理解车机导航和真实路口场景的匹配和真实的轨迹预期,而并非是理解车机导航的播发信息【现在XX米后右转】
VLA构架用了3dgs【用很多个小椭球+每个椭球一个高维度颜色来描述三维世界的,所以文字这类信息在他的表示里应该算是复杂纹理,不知道能不能用3dgs的方式高效的表达且传导给后面的llm】
现在给出的解法是用了2D Vit 和3D表征同时进VLA模型,所以确实解决了3D场景的表达理解和文字信息的表达理解。
这个细节反向证明了,目前看VLA这个构架图【真实性、透明性】就是非常非常高的

相较于原来的端到端模型重复造轮子的就小多了。E2E 500wclips 升级到800W clips 其实是重新训练的VLA司机模型 1.0 和2.0 都是来自于32B 的VL模型蒸馏后强化学习做的,本质上数据利用率会高的多的【大幅度减少了重复分析数据、匹配数据造轮子的工作】
能力提升的预测【客观来说,模型参量增加表现增强是客观存在的】。E2E模型1000W clips的模型参量大概率是 小于1B的,而VLA司机基座模型是【3.2+0.8=4B】。还有一个云端增强的32B的VL模型,大家能理解能力的增强?【复杂场景、真实理解、推理、长时序】
VLA提升的并不是E2E模型的流畅性,而是提高的顶层思维能力


